正则表达式
正则表达式(Regular Expression)是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
- 可以通过正则表达式,从字符串中获取我们想要的特定部分。
历史: 维基百科 - 正则表达式
基础语法
菜鸟教程: 正则表达式 - 语法
优先权
| 优先权 | 运算符 | 描述 |
|---|---|---|
| 最高 | \ | 转义符 |
| 高 | (), (?:), (?=), [] | 圆括号和方括号 |
| 中 | *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| 低 | ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| 最低 | | | 替换,”或” 操作 字符具有高于替换运算符的优先级, 使得”m|food”匹配”m”或”food”。 若要匹配”mood”或”food”, 请使用括号创建子表达式,从而产生”(m|f)ood”。 |
正则性能优化
正则是个很好用的利器,如果使用得当,如有神助,能省掉大量代码。当如果使用不当,则是处处埋坑。所以如何写一个高性能的正则表达式就尤为重要。
避免量词嵌套
举个简单的例子对比:
我们使用正则表达式 /a*b/ 去匹配字符串 aaaaa
我们将以上正则修改成 /(a*)*b/ 去匹配字符串 aaaaa
上两个正则的基本执行步骤可以简单认为是:
贪婪匹配
回溯
直至发现匹配失败
但令人惊奇的是,第一个正则的从开始匹配到匹配失败这个过程只有 14 步。而第二个正则却有 128 步之多。可想而知,嵌套量词会大大增加正则的执行过程。因为这其中进行了两层回溯,这个执行步骤增加的过程就如同算法复杂度从 O(n)上升到 O(n^2)的过程一般。
所以,面对量词嵌套,我们需作出适当的转化消除这些嵌套:
1 | (a*)* <=> (a+)* <=> (a*)+ <=> a* |
使用非捕获组
NFA 正则引擎中的括号主要有两个作用:
主流功能,提升括号中内容的运算优先级
反向引用
反向引用这个功能很强大,强大的代价是消耗性能。所以,当我们如果不需要用到括号反向引用的功能时,我们应该尽量使用非捕获组,也就是:
1 | // 捕获组与非捕获组 |
分支优化
分支也是导致正则回溯的重要原因,所以,针对正则分支,我们也需要作出必要的优化。
a. 减少分支数量
首先,需要减少分支数量。比如不少正则在匹配 http 和 https 的时候喜欢写成:
1 | /^http|https/ |
其实上面完全可以优化成:
1 | /^https?/ |
这样就能减少没必要的分支回溯
b. 缩小分支内的内容
缩小分支中的内容也是很有必要的,例如我们需要匹配 this 和 that ,我们也许会写成:
1 | /this|that/ |
但上面其实完全可以优化成:
1 | /th(?:is|at)/ |
有人可能认为以上没啥区别,实践出真知,让我们用以上两个正则表达式去匹配一下 that。
我们会发现第一个正则的执行步骤比第一个正则多两步,那是因为第一个正则的回溯路径比第二个正则的回溯路径更长了,最终导致执行步骤变长。
锚点优化
在能使用锚点的情况下尽量使用锚点。大部分正则引擎会在编译阶段做些额外分析, 判断是否存在成功匹配必须的字符或者字符串。类似 ^、$ 这类锚点匹配能给正则引擎更多的优化信息。
例如正则表达式 hello(hi)?$ 在匹配过程中只可能从字符串末尾倒数第 7 个字符开始, 所以正则引擎能够分析跳到那个位置, 略过目标字符串中许多可能的字符, 大大提升匹配速度。
RegexBuddy
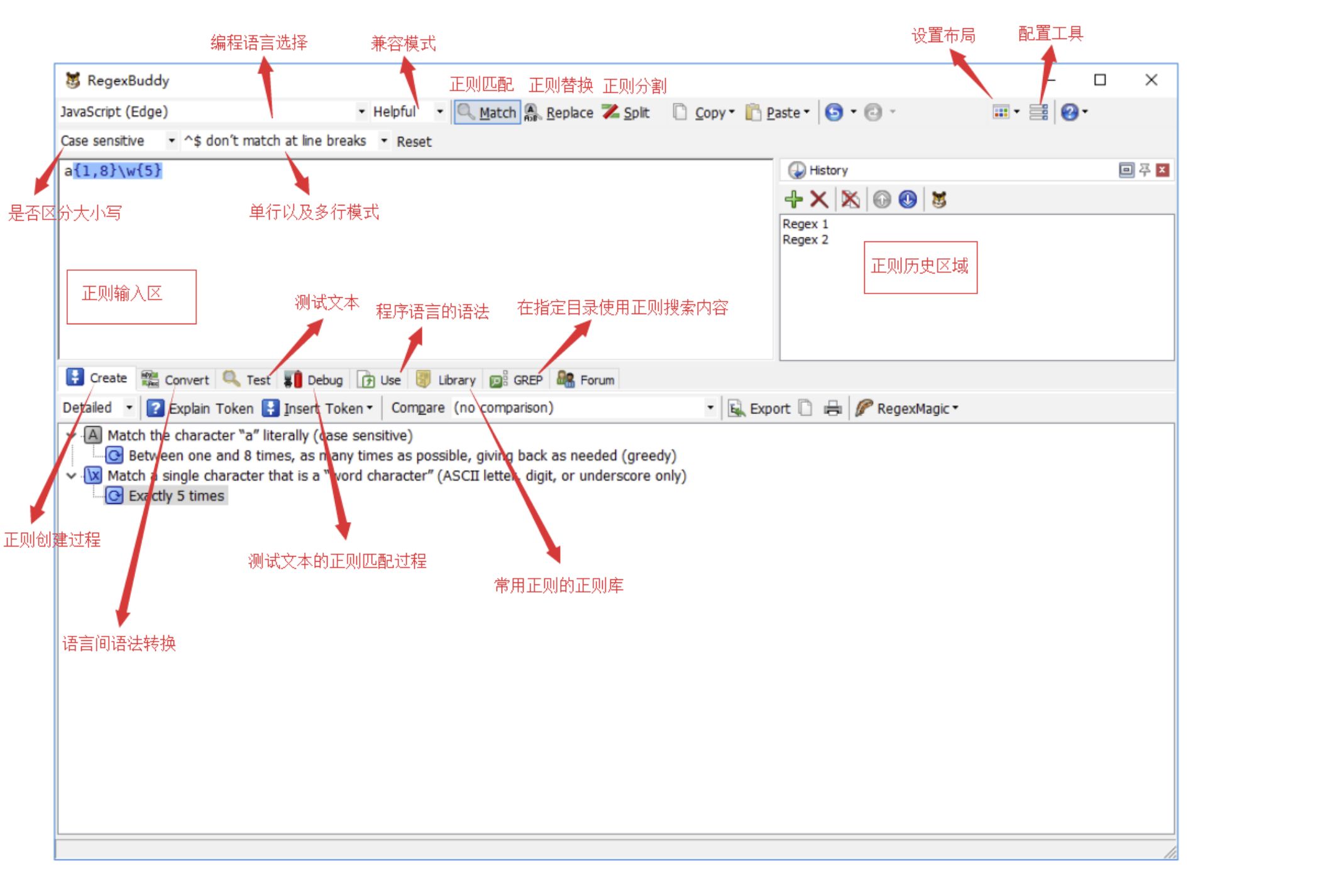
性能优化完整版: 腾讯技术工程的知乎回答
匹配中文
\w 匹配的仅仅是中文,数字,字母,对于国人来讲,仅匹配中文时常会用到,见下
中文汉字:
1 | 匹配中文字符的正则表达式: [\u4e00-\u9fa5] |
双字节(包含中日韩等):
1 | 匹配双字节字符(包括汉字在内):[^\x00-\xff] |